Custom search with Solr and Ibexa’s native Object Relation Model puts advanced information at users’ fingertips
By: Doug Plant | August 23, 2023 | Solr, index, and development
As your website grows, custom site search becomes an increasingly important way for users to quickly find the information they need.
Here at Mugo Web, we find that most of our clients’ sites evolve to the point that they want to add a custom search feature. They may simply want to provide a more seamless experience for users as they search for that one how-to blog post from seven years ago, or they may want to guide an intricate search and drill down through a scientific taxonomy.
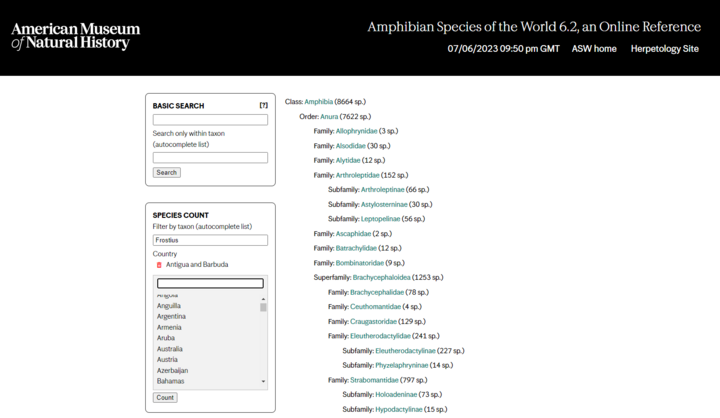
A good example of such a powerful custom search is the Amphibian Species of the World database that we built and maintain for our longtime client, the American Museum of Natural History. The site offers both basic Lucene search and a custom experience through the complex taxonomical and regional classification of thousands of records.
Our development team implements custom searches using an Apache Solr index and the Ibexa DXP’s native Object Relation Model (ORM) that communicates directly with the content database to populate the production website.
These two tools, along with a little planning and smart data design, let us create useful, highly detailed searches that simply aren’t possible using built-in search features found in commodity content management systems.
In this post, I’ll describe how we use Solr and the Ibexa ORM to build high-performance, custom searches. I’ll also show you a couple of showcase examples of how our work helps ensure that site visitors find exactly the information they want.
How important is custom site search, anyway?
The importance of site search has been a hot topic in web design circles for more than two decades, with pollsters and usability testers throwing out numbers of anywhere from 15 percent to 50 percent of site users starting a session with search. (This blog post at Optimal Workshop provides a nice overview of the debate.)
Site search becomes more important when you have a motivated audience that is looking for a specific interest or product, particularly on a site with thousands of pages. Case in point: A recent whitepaper from Hawksearch suggests that audience segments who search on ecommerce sites are five times as likely to generate revenue.
In our own work at Mugo Web, we tend to suggest a custom site search or drill-down query to site owners once they have:
- Built up an extensive content library
- Gathered data on user behavior to inform the design of the search
Of course, if we are working with a customer to re-launch their domain on the Ibexa CMS, a custom search may be part of the initial project. It all depends on the size of the content database and the desired user experience.
In some cases, we find that Ibexa’s built-in template operators – simple MySQL queries that execute against the ORM – are perfectly adequate for building pages built around canned, ordered queries, particularly if the database schema is precise. We move on to Solr when we find that a flat, NoSQL search index is the best answer for search complexity and performance.
What is Apache Solr, anyway?
Solr is an open-source enterprise platform, distributed and maintained by the Apache Foundation, that has become the de facto solution for large-scale data indexing and search.
Solr provides an API for data consumption and export, as well as a Lucene search engine for executing searches against the indexes it creates. Solr indexes are typically stored in JSON format, making them easily portable to numerous applications.
Solr indexes data in two basic units:
Documents represent a complete data record within the Solr index. They are often created from various sources, such as databases, spreadsheets, or web pages, and can contain fields that store information, such as text, numbers, dates, or geospatial data. Solr documents can have nested structures for advanced data sorting purposes.
Labels are used to tag fields in Solr documents with descriptive information that can be used for filtering or search. Labels can be created for any field and can have multiple values or be hierarchical.
To create a Solr document, the user needs to define a schema that specifies the fields and their types, as well as index and search settings. The schema can be created and managed using Solr's Schema API, which provides a RESTful interface. Once the schema is defined, the user can add content using Solr's Indexing API, which allows for bulk or individual processing.
Use cases for implementing a Solr search index
So, what are the signs that your site needs a custom search index?
- You have so much content that even simple database queries simply become too resource-intensive. This problem commonly arises in WordPress and other commodity CMSs and is one of the telltale signs that it’s time to move up to an enterprise-ready platform. Again, Ibexa’s built-in ORM eliminates this issue for our projects, but many sites simply will buckle if you keep hitting the database.
- You have different types of content in your DB and you want to integrate them into a more common, “Google-like” search experience. You might want to answer a search with both user bios and blog posts relating to a specific topic. Running a MySQL query against various content types in the DB is a huge drain on resources.
- The labeling of your data is inconsistent. Let’s say your UGC posts are labeled as having a “livedate,” and your in-house dates have a “publishdate.” Simplifying these data to have the same label in your Solr documents speeds search and allows for a cleaner presentation. This can also be useful if you are publishing content from multiple databases. However, here at Mugo Web, we prefer to replicate relevant data sets into the main DB and index from there – it’s just a cleaner approach and gives us more control.
- You publish large sets of individualized results that can’t be held in memory. The most obvious example here is user recommendation lists. There are simply too many possible instances of these to create in real time, so creating and updating flat Solr indexes is the only reasonable way to tackle this process.
- You publish complex directories of data with multiple sort options that simply can’t be supported in the basic search model. This is where we implement the most powerful custom searches, including the AMNH example depicted earlier. The relationships between the data, including the child-to-parent inheritance, just become too much to process via direct MySQL queries. So, we use Solr to create a flat index that incorporates all the needed data in a hierarchy built expressly to support the search.
I’ll walk through some specifics in a bit, but for now, let me just say WordPress and commodity CMSs simply can’t handle this.
How Solr and the Ibexa ORM work together
As with any enterprise-class CMS, the Ibexa MySQL content database and production layer are quite distant from each other. For many pages, our developers talk to the native Object Relation Model that lives between the database and the site code. The ORM pulls content data and keeps it in memory for read access by production. We generate Solr search indexes in the same manner, by speaking directly to the ORM, which uses some persistence on its side to communicate directly to the DB.
Ibexa has some built-in Solr behaviors built into its ORM to map and name Solr documents and labels, but we typically find that we need to modify that structure a bit for our custom searches. We accomplish this with 30 or 40 lines of PHP code. Our Maxim Strukov recently posted about a project where he used such code to modify the Matrix field type – it’s a good read on the flexibility available in that tool.
The ORM checks for deltas and updates the Solr index when content is added or modified in the DB. You could schedule these checks to run in a batch, but I honestly cannot remember the last time we built a custom search in this fashion. A big advantage of building on a platform like Ibexa is native, optimized functionality like the ORM for just this purpose.
When a user or page executes a query, we do a Lucene search against the flat Solr index.
Industry benchmarking places Solr at 50x or faster than SQL-based queries, even for simple use cases – Apache tends to describe it as being simply “magnitudes” faster. I’ll just say Solr makes resource use and performance for complex searches like the Amphibians database a non-issue. With MySQL, this would be a non-starter.
Solr custom search in action on the AMNH Amphibians database
There are more than 8,600 species of amphibians around the world, each falling within a liner taxonomical structure of Class | Order | Family | Genus | Species (which the occasional superfamily and subspecies thrown in to make things interesting, of course). The Amphibian Species of the World database holds citations, academic research, and links to external resources about all these species. Mugo Web has helped AMNH maintain the site for about 10 years, and we often make changes to support new research and demands from users.
The content-database schema is set up in three parts – taxon, authors, and references. It’s a very complicated data structure and there is no way to effectively cache results because they are driven by a near-infinite number of possible queries.
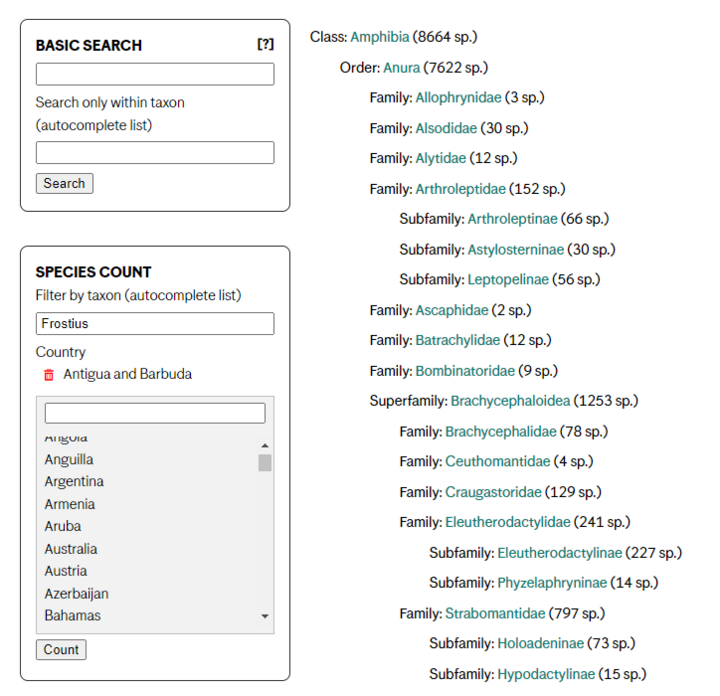
The site’s primary navigational interface is a hierarchical listing of the species, with counts for each taxon. We could execute this main navigation with Ibexa’s template operators, although Solr does provide a major advantage in speed. The ORM is really quite powerful – we don’t always use Solr, even for high-traffic sites, if the relationship between content objects is predictable. (The Bible Lessons feature we built for The First Church of Christ, Scientist is a good example of a multi-object page we publish without a Solr index).
The complexity of the Amphibians database comes into full play when users execute individual text searches. As you can see below, user searches are executed as basic Lucene queries, with the option to limit results to a given taxon.

Even the most basic searches can result in highly cross-referenced and complex results. There are a lot of tree frogs out there.
Recently, we added a country data/filter to the site, which required us to:
- Change the querying interface
- Change the editing interface
- Add a new country field label to the PHP plugin that instructs the ORM on how to build the Solr index.

The Species Count feature is a great example of how Solr can support extremely complicated searches. The taxons themselves do not carry the data – frogs live in trees all over the world, so country is assigned on a species level. A MySQL search for tree frog genuses in various areas would need to scan across various content structures and hierarchies to produce results. It’s simply not feasible.
Instead, we create a Solr index that encompasses all the needed document/label info needed to seamlessly support the search
The next time we add features to the site (and we will), we can change our plugin and rebuild the Solr index to meet requirements.
Considerations for designing a custom search
While custom searches are great for exposing data to your website’s audience, there are some design considerations to keep in mind as you evaluate adding the feature to your site.
Data design is key
I’ve talked about how fast Solr searches are, but keep in mind that’s because the logic that drives the searches is relatively simple. Unlike MySQL, you can’t write queries that jump between content types and other schema divisions. Designing the Solr index to support the exact requirements of your search is paramount. You can code to change the index, of course, but keeping it as clean as possible cuts down on maintenance and makes the solution more scalable.
Less is more
In keeping with my last point, we most often don’t pull in the entire content database to the Solr index. If it’s not going to be used, it’s just going to get in the way – not in terms of site performance, necessarily, but in terms of unnecessary complication if you do decide to make changes in the future. In many cases, we simply rely on Ibexa’s ORM and template operators to pull in simple data, like author information.
Make interface decisions based on audience feedback
To the casual user, being able to search for the exact scientific name of amphibian species may seem unnecessary. But for the AMNH, it’s essential – its database is the canonical source for this information globally. As developers, we here at Mugo Web often advise our clients to prove the business usefulness of new features before committing to development dollars, but in the case of custom searches, cost-to-build is nominal. UX is the real issue — too many options can be confusing for all but the most sophisticated users. Base your design on user feedback.
Custom search for any data-driven experience
Custom search against a carefully designed Solr index is a powerful way to combine and elevate complex content for your site visitors. We’ve used it to support a wide variety of complex data-driven websites, including a directory of chemical cleaning agents for safety and regulation reference. With the proper attention to design and UX, the application of custom search is almost limitless.