Custom search filter options built into the CMS make for better UI
By: Benjamin Kroll | August 8, 2023 | Solr, ReaderBound, and User experience
Your website can have the best data in the world, but it quickly loses value if your users struggle to find it. Solid search features and intuitive filtering options can increase discoverability and lead to more sales.
We’ve helped several of our partners by creating better solutions for searching to address this issue. Our book publisher clients using the ReaderBound platform have very rich data sets they need to make use of for discoverability, presentation, and sales.
To support their needs we’ve built a feature on top of our search stack (Lucene, Solr, and eZ Find) that lets them create custom book collections with complex filter criteria by simply selecting filters from a list. In a nutshell, editors can write query fragments, store these in a library, and then compose them to instantly create a new (and automatically maintained) collection.
Think “Award Winners”, “New Release”, and “Poetry eBooks”. Having recognizable and relevant filterable categories helps customers discover more titles. With an improved search user experience, they might even find things they didn’t know they were looking for.

In this case, good front-end UI starts in the back-end. We developed a way for our clients to build and customize these lists easily, which will in turn help their customers and their sales.
Client/developer benefits
Our solution has multiple long-term benefits for both the client and the developer.
On the client’s side, their workflow is improved. They don’t have to contact their developer each time they need a new book listing. The feature allows them to build book listing pages using subsets of their data directly.
On the developer’s side, creating new book listing pages no longer requires new templates or override conditions for each use case. Client support is also improved, as new filters can be added or updated easily to cover new use cases.
Feature parts explained
The feature is made up of three key parts: filter rules, filters, and filtered title listings. All three are trivially implemented as standard content objects and have full CMS support (organized storage, content engine support, edit history, create, edit, delete, and so on).
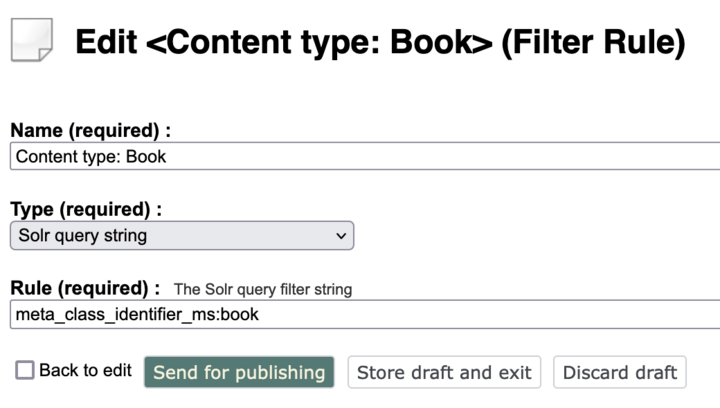
A filter rule defines how to filter a search query. For example, a "Content type: Book" filter rule could be "meta_class_identifier_ms:book" which is the Solr syntax for eZ Find’s Solr field name for eZ Publish content class identifiers and the identifier of the example “Book” content class.
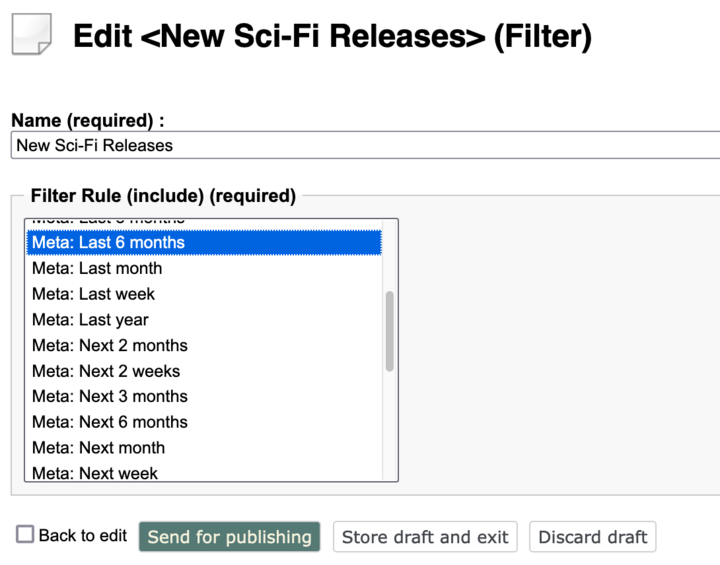
A filter is a group of filter rules, making it easier to re-use a combination of rules. For example, a "New Sci-Fi Releases" filter could combine
- Content type: Book
e.g. meta_class_identifier_ms:book - Book category: Sci-Fi
e.g. attr_category_s:(‘Sci-Fi’) - Publication date: within the last six months
e.g. meta_published_dt:[NOW-6MONTH/DAY TO NOW+1DAY/DAY]
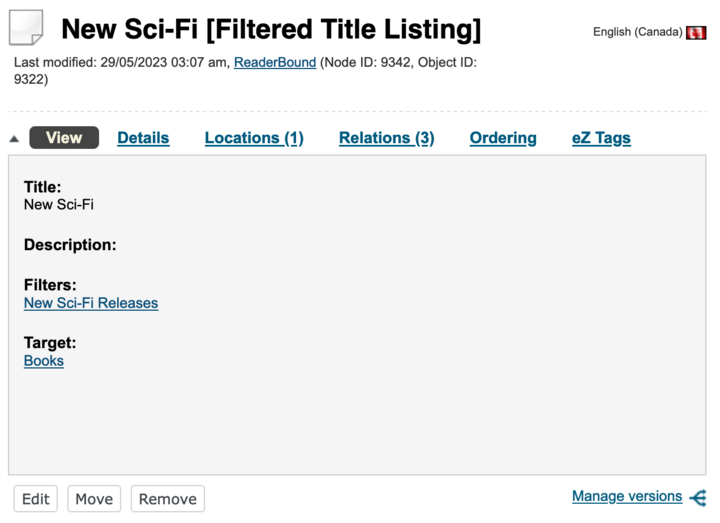
A filtered title listing uses filters and a source subtree to fetch content using eZ Find fetches. For example a "New Sci-Fi" filtered title listing would use the "New Sci-Fi Releases" filter and show titles from the publisher’s entire catalogue.
Filtered title listings are the only part of the feature that are accessible on the front end. They use a standard template, but define custom cache handling. More on this below.
Filter rule types
The system supports three types of filter rules:
Solr query string
A string using Solr’s query syntax.
e.g. content from the last calendar year
meta_published_dt:[NOW/YEAR TO NOW+1YEAR/YEAR]
Solr query string with strtotime() tokens
A string using a combination of Solr’s query syntax and PHP’s strtotime() tokens.
e.g. content from this calendar week
meta_published_dt:[%monday this week% TO %sunday this week%]
Pre-defined filter key
A string used by template/back-end code to identify and apply a hard-coded filter.
e.g. content that requires an external lookup value
lookup_external:acme_systems
Setting up a filtered title listing
A publisher creates a new filter, combining three existing filter rules:
- Content type: Book
- Book: Status: Published
- Book: Release date: Last six months
They then create a new filtered title listing, select one or more filters and target the location the data should be fetched from.
The target could be the location containing all their books, a category, a series, an imprint, or a manually curated list.
Technical details
As noted earlier, the different feature pieces are very simple content objects, using text line or object relation list attributes.
The filtered title listing template contains all the logic to fetch the filter and filter rule objects. It also handles how the different types of targets translate to filter strings and combines that information with the strings from the filter rules.
The publisher’s filter parts translate to:
- meta_class_identifier_ms:book
- attr_publication_status_s:04
- attr_publication_date_dt:meta_published_dt:[NOW-6MONTH/DAY TO NOW+1DAY/DAY]
- meta_path_si:123
The whole process top to bottom:
- fetch filter relations
- fetch filter rule relations for each filter
- add target subtree ID
- combine everything into the final filter string
- fetch content
All parts are concatenated by “and” before being handed over to eZ Find, leaving us with a final filter string of:
meta_class_identifier_ms:book AND attr_publication_status_s:04 AND attr_publication_date_dt:meta_published_dt:[NOW-6MONTH/DAY TO NOW+1DAY/DAY] AND meta_path_si:123
Filtered title listing and caching
As filtered title listing pages are backed by content objects, the standard view cache system applies. This results in the information shown becoming stale over time.
To mitigate the issue, the view template sets a custom cache TTL to strike a balance between up-to-date information and performance.
As publishers only update their data a few times a day, this is an acceptable compromise.
Caveats and cautions
Some filter rule combinations may not work as expected as all parts of a filter are concatenated by “and”. To work around this limitation, specific single use filter rules can be created, using brackets for grouping, and/or combinations or exclusions.
Example: A single rule to show books from two series, but exclude digital formats
or titles from the Sci-Fi category.
( attr_series_si:(1001 2002) AND NOT ( attr_product_form_s:(digital) OR attr_categories_si:(3030) ) )
Mugo Web can help you build better UX on your site
With this solution, our publishing clients now have a better way to showcase their data and their customers have a better experience finding titles based on their interests.
Increasing the usability of your data sets can be an easy way to add value to your site. If you are looking for a development partner who understands your needs and the needs of your customers, reach out to us today!